Bayer's preclinical scientists spend a meaningful share of their time hunting through decades of historic study reports, most of them locked in PDFs that keyword search handles poorly. PRINCE, a platform Bayer built with Thoughtworks, was designed to close that gap, and its architecture is a useful case study in what it actually takes to make a multi-agent retrieval system dependable rather than merely demonstrable.
From Keyword Filters to a Research Assistant
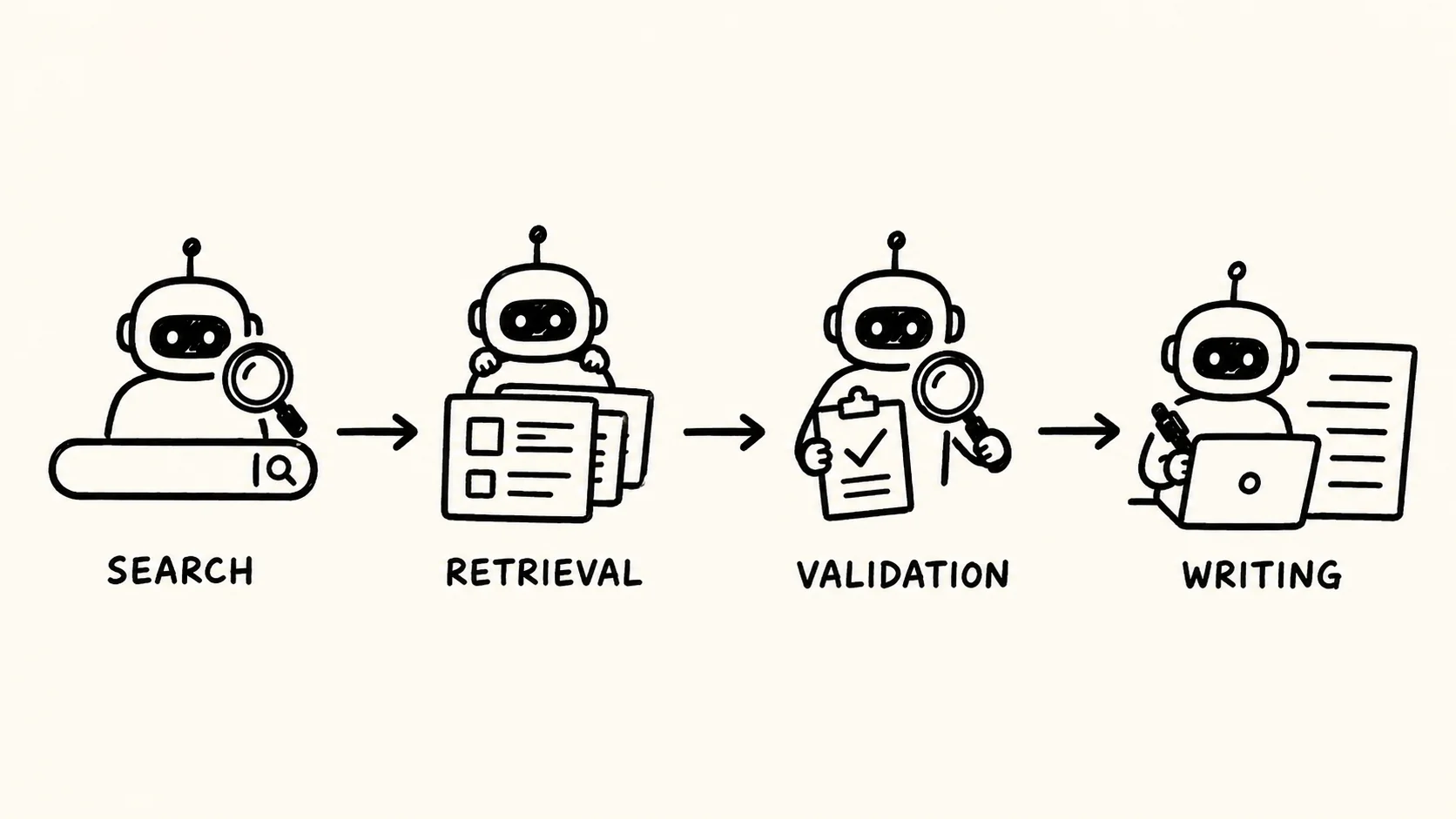
PRINCE did not start as an agentic system. It moved through three distinct phases, each one solving a different limitation of the version before it. The first phase, internally called "Search," gave researchers a single gateway across fragmented data silos, using structured metadata and rigid filters rather than free text. The second phase, "Ask," added standard retrieval-augmented generation so researchers could query unstructured historic PDFs in natural language. The third phase, "Do," is where PRINCE stopped being a query tool and became an active research assistant, using a multi-agent system to handle compound tasks such as drafting sections of regulatory documents.
That progression matters because it shows the team treating agentic capability as an escalation, not a starting point. Search and retrieval had to work reliably before delegation to autonomous agents was added on top.
Splitting Retrieval Before Splitting Agents
The Phase 3 workflow is orchestrated through LangGraph and FastAPI, and it is structured as a sequence of agents rather than a single model call. A request first goes to a step that clarifies user intent and sets the boundaries of the prompt, then to a planning step that formulates an execution strategy. From there, a Researcher Agent does the actual retrieval, and it deliberately uses two separate paths: OpenSearch for vector embeddings drawn from the unstructured study reports, and AWS Athena for text-to-SQL queries against curated structured data. That split exists because preclinical data at Bayer is not one shape of data; some of it lives in narrative PDFs that benefit from semantic search, and some of it lives in structured tables that are better served by a query that returns exact rows.
What comes after retrieval is the part that distinguishes PRINCE from a standard RAG pipeline. A Reflection Agent checks whether the retrieved evidence is actually sufficient and valid before anything gets written. If the context is missing or appears faulty, the system triggers a context-aware retry or asks the user for clarification rather than letting a Writer Agent synthesize an answer from incomplete evidence. Only once that check passes does the Writer Agent package the verified evidence into a final, formatted response.
Context Discipline, Not a Bigger Context Window
A recurring theme in PRINCE's design is a distinction the team draws between context engineering and harness engineering. Harness engineering is the orchestration layer: tool boundaries, state tracking, and fallback behavior, handled by LangGraph and FastAPI. Context engineering is about discipline rather than capacity — instead of dumping all available data into one large context window, each agent receives only the slice of context relevant to its job. The planning step works with the task definition and prior turn. The Researcher Agent works with retrieval queries and tool specifications. The Writer Agent works with verified evidence only, not the raw retrieval output or the planning chatter that preceded it.
This separation is also what makes the retry loop in the previous section affordable. Because the Reflection Agent's job is narrow — judge sufficiency, not generate prose — it can run that check cheaply and repeatedly without re-exposing every downstream agent to the full retrieval payload each time.
Designed to Fail Without Going Down
PRINCE's reliability work extends past the agent graph and into the infrastructure underneath it. Node-level execution states are checkpointed in PostgreSQL through a LangGraph checkpointer, while broader application state runs through DynamoDB, so a failed step does not mean losing the whole session's progress. Model calls route through an internal GenAI gateway that exposes OpenAI, Anthropic, and Google models behind one endpoint, with multi-tier retries at both the individual LLM call level and the workflow node level. If one provider is degraded or unavailable, traffic shifts to an alternative model behind the same gateway rather than surfacing an outright failure to the user.
On the observability side, AWS CloudWatch covers general system health, while Langfuse handles production tracing of individual agent runs. Live traffic is checked daily against the RAGAS evaluation framework, and the team runs regression datasets specifically when core prompts or workflow logic change, rather than relying on spot checks alone.
What stands out across PRINCE's design is how much of the engineering effort sits outside the model itself. The retrieval split, the reflection gate, the context limits per agent, and the gateway failover are all decisions about what happens around the LLM calls, not about prompting the model more cleverly. For teams building similar systems on top of unstructured technical archives, that is the more transferable lesson than any single tool choice.
Why Japan Is Losing the AI Race It Helped Create
From language tokenization barriers to corporate risk aversion and venture capital gaps, this explainer breaks down why Japan's AI position lags the US and China.

Google Fires DevRel Engineer Over Workspace CLI
Justin Poehnelt says Google fired him for building a Workspace CLI under the official GitHub org, two days before Google unveiled its own version.
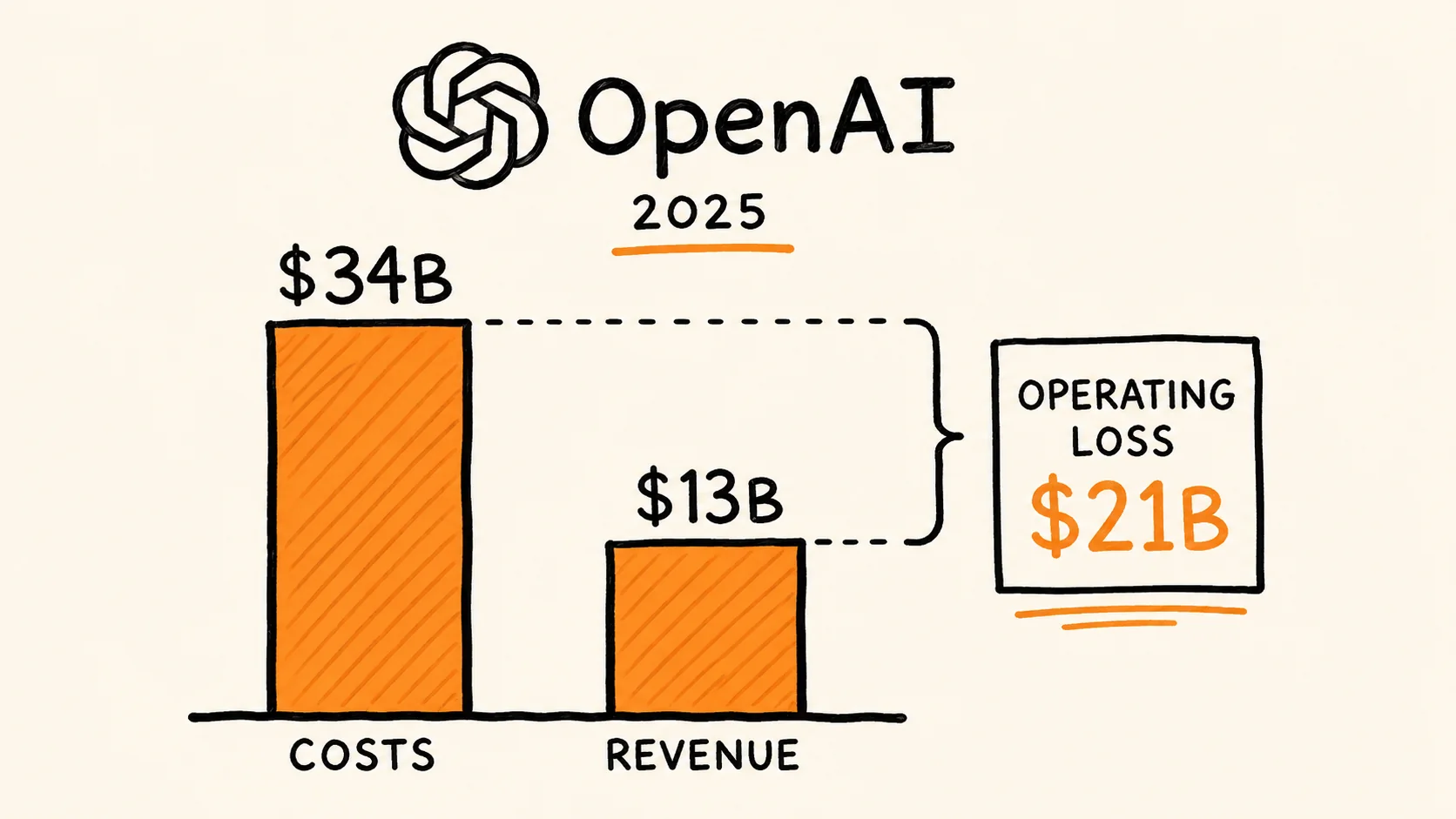
The AI Subsidy Era Is Ending — and Enterprise Buyers Are Getting the Bill
A data-grounded analysis of the AI subsidy model's structural unsustainability, OpenAI's 2025 financial losses, and the 2026 pivot to token-based pricing that is already shocking enterprise customers.

Honor's X80 Pro Max Pairs an 11,000mAh Battery With a Two-Year Free Screen Warranty
Honor launched the X80 Pro Max in China on June 22, 2026, with a record battery, SGS-certified drop resistance, and a free two-year screen warranty.
Comments (0)
Please sign in to join the discussion.
No comments yet.
Be the first to share your perspective on this topic.