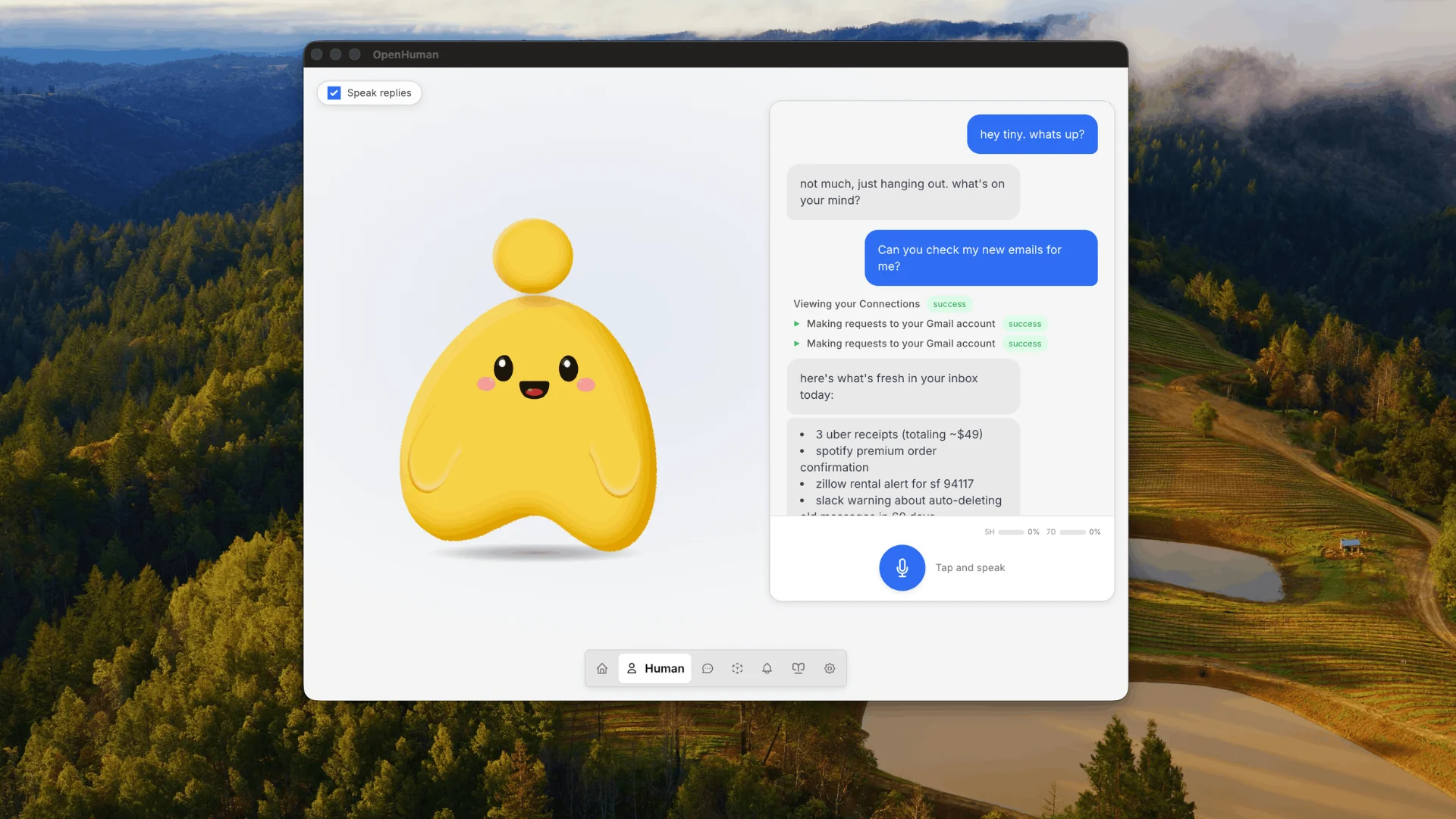
OpenHuman, released by tinyhumansai under a GNU license, is a desktop-first agentic assistant that fetches and locally indexes data from more than 118 connected services on a continuous 20-minute loop — without routing that context through an external cloud store.
A UI-First Architecture Aimed at Reducing Setup Friction
Most open-source agents require developers to configure models, set environment variables, and manage API keys before a first run. OpenHuman's stated design priority, described in its documentation, is to replace that flow with one-click OAuth connections and a visual interface. The project describes this as a "UI-first" approach.
The tradeoff is build complexity. Compiling OpenHuman from source requires Node.js 24 or later, pnpm 10.10.0, Rust 1.93.0 with both rustfmt and clippy, CMake, Ninja, and ripgrep. The project bundles Tauri and Chromium Embedded Framework sources as vendored git submodules, meaning a recursive git clone is necessary before any build step begins. For developers accustomed to npm install workflows, that prerequisite chain is a meaningful barrier.
The project is in early beta, and its GitHub repository notes that rough edges should be expected.
How the Memory System Stores and Surfaces Context
OpenHuman's memory layer is described in the documentation as inspired by Andrej Karpathy's personal Obsidian wiki workflow. Incoming data from connected services is parsed into Markdown chunks of 3,000 tokens or fewer, scored, and arranged into hierarchical summary trees. Those trees are stored in a local SQLite database — meaning the index lives entirely on the user's machine.
The same data is simultaneously written as standard .md files into a local vault that is compatible with Obsidian, allowing users to browse, search, and edit their agent's context directly without going through the assistant interface. This separation matters in practice: the SQLite tree is what the agent queries during inference, while the Markdown vault is what the user can inspect and correct. If the agent has indexed something incorrectly, the vault provides a direct path to fix it.
An optional configuration in config.toml connects OpenHuman's memory store to agentmemory, a backend proxy that allows the same durable context to be shared with other coding agents — including Claude Code, Cursor, Codex, and OpenCode. This interoperability layer is optional and requires manual configuration.
TokenJuice Compression and What It Actually Does
Every payload that enters the agent — tool results, scraped web pages, email bodies — passes through a layer the project calls TokenJuice before reaching the LLM. According to the documentation, TokenJuice converts HTML to Markdown, shortens long URLs, and strips non-ASCII characters. The project claims this reduces LLM token costs by up to 80%.
That figure comes from the project itself and has no cited third-party benchmark. What the mechanism does is straightforward and standard: HTML-to-Markdown conversion removes tag overhead, URL shortening trims long parameter strings, and ASCII-only filtering removes characters that consume disproportionate tokens in some tokenizers. The practical effect depends heavily on the type of content being processed — a plain-text email gains little, while a dense HTML page with embedded scripts gains substantially.
For developers building on top of the agent or running it at volume, the compression layer also reduces latency, since fewer tokens mean shorter prefill times regardless of per-token cost.
Capability Surface: What Ships by Default
OpenHuman bundles several categories of tooling without additional configuration. Native web search and web-fetch scraping are included. Local filesystem access covers git operations, linting, test running, and grep-style search. Voice interaction uses Speech-to-Text natively alongside ElevenLabs Text-to-Speech with lip-sync support on the desktop mascot. The mascot itself is an interactive visual element with a rendered face that reacts to context, speaks aloud, and maintains persistent memory across weeks of use. It can also join Google Meet sessions as a participant, according to the project documentation.
Model routing is handled automatically: the agent maps tasks to specialized LLMs based on task type — reasoning-heavy queries, latency-sensitive requests, and vision tasks each route differently under a single unified subscription. Local inference through Ollama is supported as an optional alternative for workloads where users prefer fully on-device processing.
The integration list covers Gmail, Notion, GitHub, Slack, Stripe, Google Drive, Linear, and Jira, among others, all connected via one-click OAuth. This is a broader surface than most self-hosted agent projects offer out of the box, though the quality and depth of each integration are not detailed in the available documentation. Developers evaluating the project for specific workflows should verify individual integration behavior rather than assuming uniform capability across all 118 listed connectors.
For context on how this fits within the broader landscape of self-hosted tools, a survey of 135 open-source AI research tools covers related agent and automation projects in more depth.

How to Build a Real-Time Indexing Pipeline With Redis and PostgreSQL 19
A production-honest walkthrough of a Postgres-to-Redis indexing pipeline, including the 8KB NOTIFY limit, pending-message reclaim, and when to use logical replication instead.

Redis, Valkey, Dragonfly, and Tellstone: One Thread vs. Many, Explained Simply
Redis forked into Valkey in 2024. Dragonfly rebuilt the engine multi-threaded. Tellstone is a tiny Go experiment. Here's what actually differs.

PostgreSQL vs DynamoDB: When to Switch and How Much It Costs at Scale
AWS's own price list shows DynamoDB on-demand costing 26x more than provisioned, and RDS PostgreSQL swinging hard on Multi-AZ and reserved-instance terms.

How Discord's Gateway Handles Millions of Concurrent WebSocket Connections
Discord's gateway scaled past 12 million concurrent WebSocket users with one Erlang process per session. Here's how the real architecture works.
Comments (0)
Please sign in to join the discussion.
No comments yet.
Be the first to share your perspective on this topic.