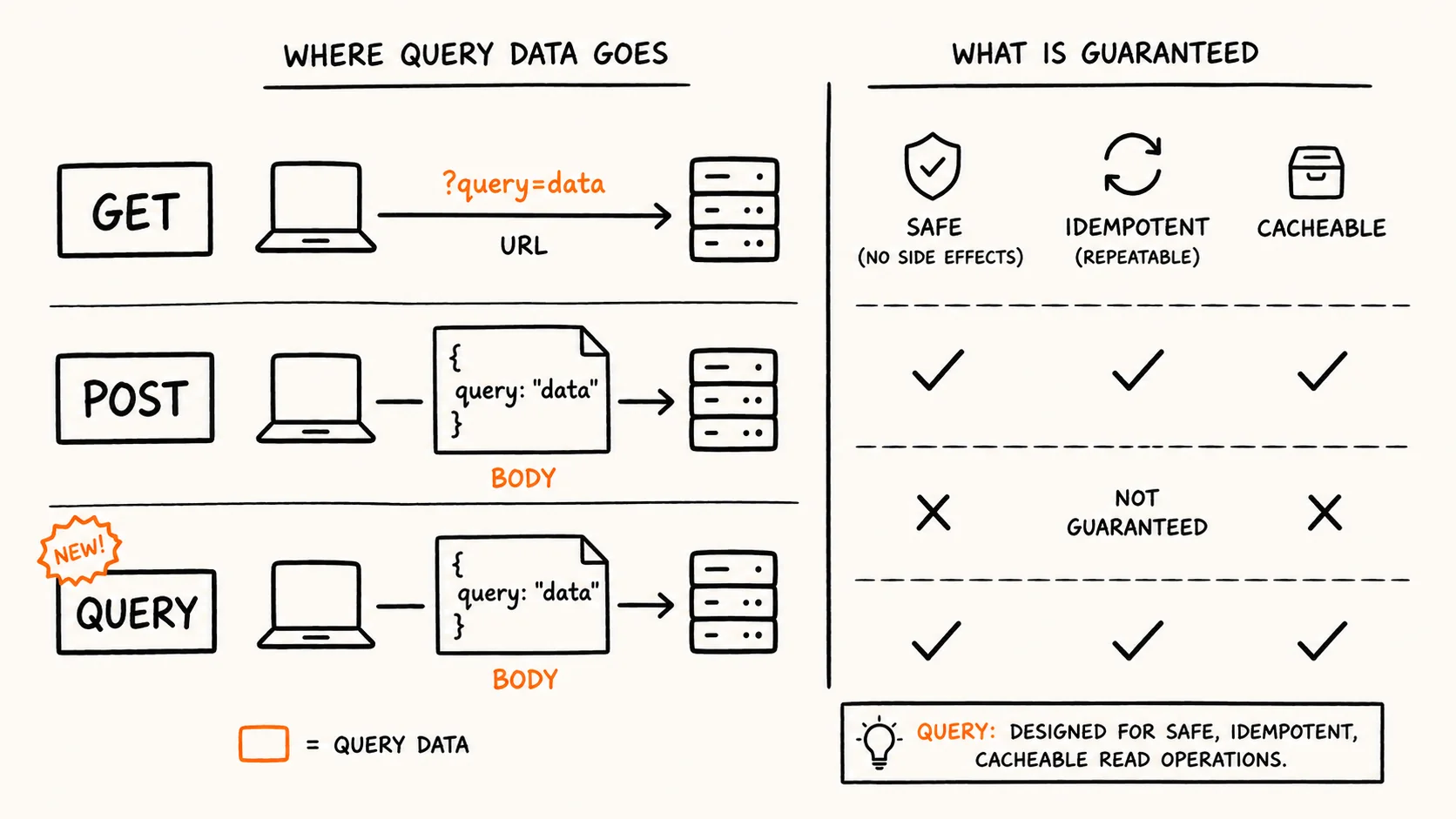
The IETF has published RFC 10008, standardizing a new HTTP method called QUERY that lets clients send query data in a request body while keeping the safety and caching guarantees normally reserved for GET.
Why GET Stopped Being Enough for Complex Queries
For as long as HTTP has existed, querying a server has mostly meant putting parameters into a URI's query string and sending a GET request. That pattern breaks down once the query itself gets large or sensitive. URIs pass through many uncoordinated intermediaries, so there's no reliable way to know a safe size limit in advance, and encoding structured data into a valid URI carries its own overhead. URIs also tend to get logged or bookmarked far more readily than request bodies do, which becomes a problem the moment query parameters contain anything sensitive.
Developers worked around this for years by sending queries through POST instead, putting the input in the request body rather than the URI. The tradeoff was that POST carries no guarantee of safety or idempotency, so a client or intermediary has no way to know, without out-of-band knowledge of the specific server, whether retrying a dropped POST request is safe or might cause a duplicate state change. That ambiguity is exactly what blocks automatic retries and certain caching behaviors for POST-based queries.
QUERY is built to close that gap. The request body works like POST's, but the method is explicitly defined as safe and idempotent, the same properties GET already has. A request that previously needed GET /feed?q=foo&limit=10 can become a QUERY request with the same parameters carried as form-encoded content in the body instead of the URI, while keeping the safety contract clients depend on for retries and caching.
How a Server Tells the Client Where the Results Live
QUERY doesn't just move data from the URI into the body. The specification also defines what RFC 10008 calls the equivalent resource: a resource that responds to GET, represents the original QUERY request and its target, and accounts for both the request content and its metadata. A server isn't required to expose this resource at a URI, but if it does, two existing HTTP response fields take on new meaning in a QUERY response. Content-Location can point to a URI holding the specific result just returned, while Location can point to a URI that will repeat the same query operation on a future GET request, without the client needing to resend the original query body.
That distinction matters for caching in particular. A cache for QUERY responses has to read the full request body to build a cache key, since the query terms live there rather than in the URI, which the specification acknowledges is inherently more complex than caching a GET. If a server supplies a Location field pointing to an equivalent resource, a client can switch to plain GET requests for that same query going forward, sidestepping the body-based cache-key problem entirely.
Where Requests Get Rejected Before Reaching the Query Logic
RFC 10008 puts most of its specificity into how a server must handle a mismatched or missing Content-Type field, since the request body has no defined meaning without it. The rule itself is short: a server must fail a QUERY request outright if Content-Type is missing or inconsistent with the request content. The specification then separates that single rule into distinct failure paths, each pointing to a different status code depending on what exactly went wrong.
A request with no media type information at all is incorrect by definition and gets a generic 400 (Bad Request). A request whose declared media type isn't supported by that particular resource, even if the type is a real and well-known one elsewhere on the web, gets 415 (Unsupported Media Type), and the server can use the new Accept-Query response field to tell the client which types it does support. A request where the declared Content-Type doesn't match what's actually in the body gets 400 as well, and the specification is explicit that a server isn't permitted to guess at the real type by inspecting the content, a practice it calls content sniffing. Only once the type is both supported and consistent does the server move on to evaluating the query itself, where a syntactically valid query that fails for content reasons, the RFC's own example is a SQL query naming a table that doesn't exist, gets 422 (Unprocessable Content) instead.
As a Proposed Standard published this month, QUERY's reach depends on adoption by servers, frameworks, and browsers. The RFC notes one concrete adoption hurdle already built into the web platform: because QUERY isn't among the methods CORS treats as safelisted, cross-origin requests using it will trigger a preflight check, the same overhead currently associated with custom HTTP methods.
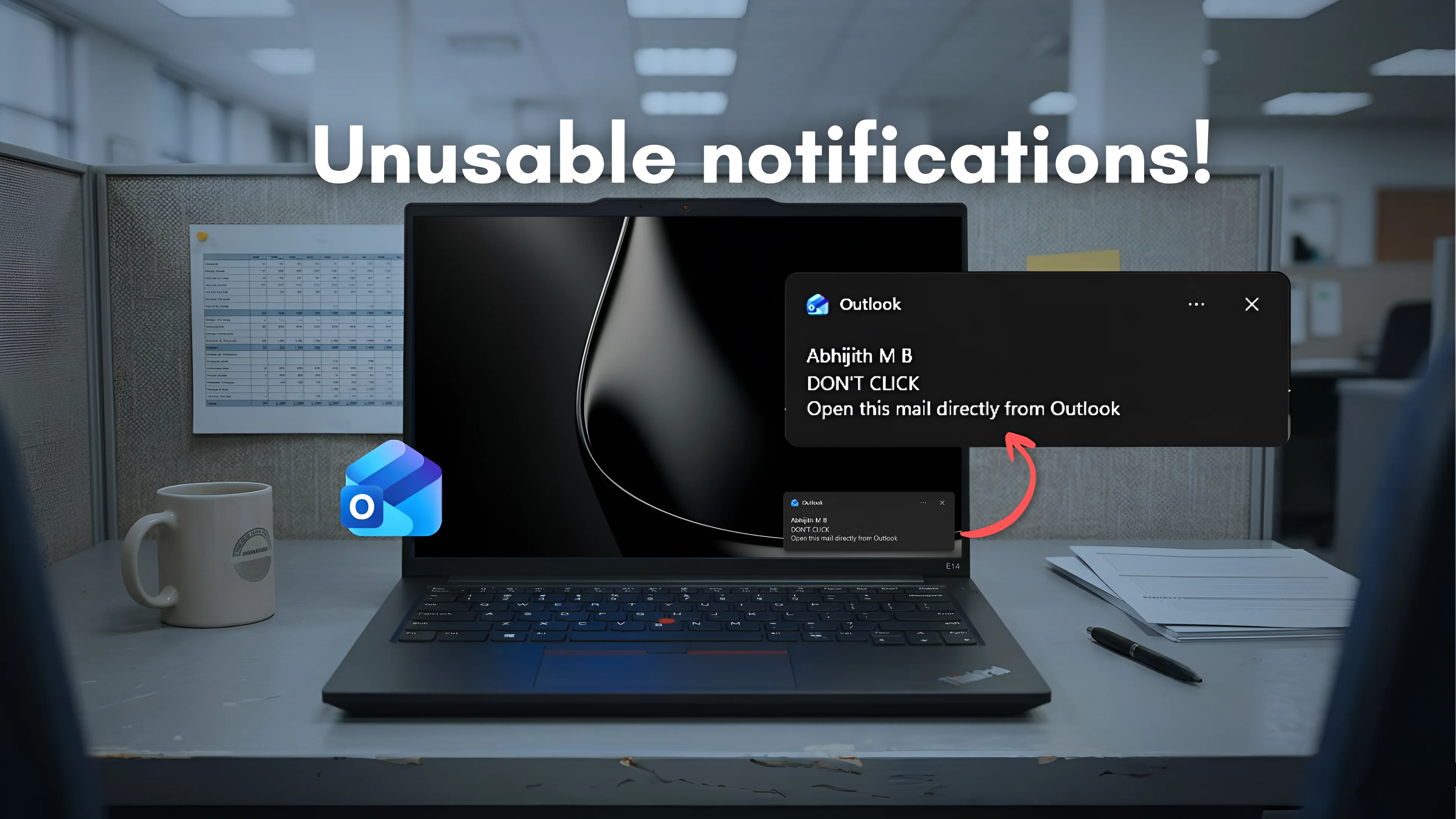
New Outlook WebView2 Architecture Causes 10-Second Notification Delay
New Outlook's reliance on WebView2 forces a heavy initialization process for basic tasks, contrasting sharply with the efficiency of native Win32 applications.

Only 16% of Americans See AI as a Net Positive
Pew Research data shows 16% of Americans expect AI to help society long-term, while a parallel Gen Z survey finds rising daily AI use paired with growing distrust of its societal impact.
Epic Games Launches Lore, an Open VCS for Game Studios
Epic's new Lore VCS uses Merkle trees, content addressing, and exclusive locks to handle binary game assets that have long pushed studios toward Perforce.

Chrome 150 Ends Last MV2 Workarounds for Ad Blockers
Chrome 150 removes the ExtensionManifestV2Disabled flag on June 30, 2026. Chrome 151 follows in July with full MV2 removal. uBlock Origin and legacy ad blockers lose their last workaround.
Comments (0)
Please sign in to join the discussion.
No comments yet.
Be the first to share your perspective on this topic.