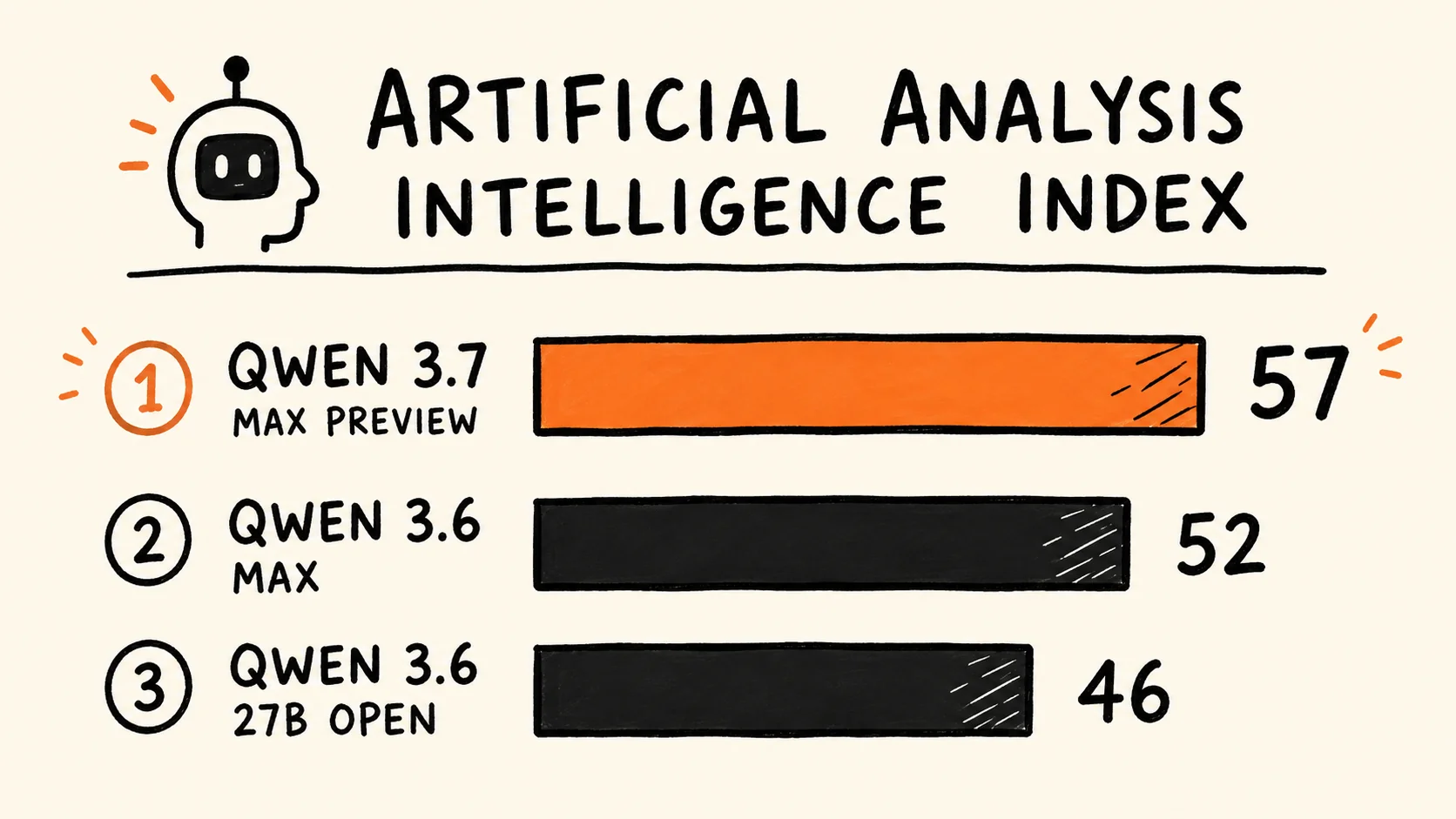
Alibaba's Qwen 3.7 Max-Preview landed on its API on May 19, 2026, five days before the Alibaba Cloud Summit, and scored 57 on Artificial Analysis's Intelligence Index — placing it first among 218 ranked models. The open-weight variants developers are waiting for have been announced but carry no release date yet.
What Artificial Analysis Is Measuring With That 57 Score
Artificial Analysis published its evaluation of Qwen 3.7 Max on May 19, 2026. The headline figure — 57 on the Intelligence Index — represents a five-point improvement over Qwen 3.6 Max Preview's score of 52 under the same methodology, and it claims the top position out of 218 ranked entries on AA's public leaderboard.
The Intelligence Index is not a single test. It aggregates performance across ten evaluations: GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity's Last Exam, GPQA Diamond, and CritPt. A model that improves on five of those ten and holds steady on the rest can move the aggregate by several points. What drove the +5 gain for Qwen 3.7 is not broken out in the available reporting, so the score confirms improvement without specifying where.
One detail in the AA data is practically important for anyone considering the Max API: during evaluation, Qwen 3.7 Max generated 97 million output tokens against a median of 26 million for the evaluated set. AA describes it as "very verbose in comparison to the average." Reasoning models routinely produce long chains of internal thought before arriving at an answer, but Qwen 3.7's verbosity sits at the high end of that category. For API users paying per output token at scale, that is a cost variable worth pricing in before deployment. The chart below shows how AA scores compare across three points in the Qwen 3.x lineage.
Where Qwen 3.7 Max-Preview Ranks in Arena — and What That Ranking Measures
Alongside the Artificial Analysis results, Qwen 3.7 Max-Preview appeared on Arena AI's text leaderboard on May 14, 2026. As of May 20, the model held an Elo score of approximately 1,489 at rank #14 overall. Earlier reports over the preceding 48 hours cited 1,475 Elo at #13, suggesting the position has been fluctuating as more pairwise comparisons accumulate — normal behavior for a recently added model.
Arena AI, formerly Chatbot Arena, uses blind crowd-sourced head-to-head comparisons rather than standardized tests. An Elo of 1,489 at #14 places Qwen 3.7 Max-Preview behind models like Claude Opus 4.7, which typically occupies Arena's top five and holds a dominant position on SWE-bench Pro (64.3%). The #14 overall ranking does not contradict the #1 Artificial Analysis position — the two systems measure different things. AA aggregates performance on structured technical evaluations; Arena captures whether real users prefer one model's responses over another's in open-ended conversation.
The more informative signal from Arena is the category breakdown. Qwen 3.7 Max-Preview ranks #7 in Math, #9 in Expert Prompts, and #9 in Software and IT. The Math position is worth noting specifically: mathematical reasoning has historically been a strength of models like Gemini 3.1 Pro, and Arena's Math ranking reflects human preference for how a model explains and communicates mathematical reasoning, not multiple-choice accuracy alone. A #7 position in that category suggests the model's mathematical output is genuinely more useful to users than its overall rank implies. The comparison with Gemini 3.5 and related frontier models from Google I/O 2026 is worth tracking as Arena's 3.7 evaluation matures.
One structural constraint shapes how these Arena numbers should be read: the current preview forces users into deep-thinking mode and disables web search and code interpreter tools. That means the Arena comparisons so far reflect pure reasoning output, not the tool-augmented behavior that will characterize the full release. If the full Qwen 3.7 enables those features, category rankings — particularly Software and IT — may shift from where they stand today. The chart below maps the category rankings so the pattern is visible at a glance.
The Open-Weights Gap and What Developers Should Actually Wait For
For developers running local inference, the Max benchmark numbers are reference points, not targets. Alibaba has announced open-weight variants at 27B (dense) and 35B (MoE) but has not given a release date, and no weights or GGUF files were available as of May 20, 2026.
The practical signal comes from how Qwen 3.6 played out. Qwen 3.6 Max Preview scored 52 on Artificial Analysis; the open-weight 27B came in at 46 — a six-point gap under the same methodology. If Qwen 3.7 follows the same pattern, the open 27B would land around 51 AAI. That would make it roughly equivalent to Qwen 3.6 Max Preview in aggregate intelligence score, which is a meaningful improvement over the current open-weight best — but it is an extrapolation, not a confirmed figure, and Alibaba has not claimed parity between the tiers.
The architecture for the 27B and 35B has not been announced. Based on prior Qwen 3.6 releases, the 27B is likely to remain dense and the 35B a Mixture-of-Experts configuration, but neither is confirmed. VRAM requirements, GGUF availability, and compatibility with existing inference tooling like llama.cpp and vLLM will only become clear once weights land. Developers currently running Qwen 3.6 on 24GB cards have a working stack; the practical question is whether the open 3.7 variants will require the same hardware profile or a larger one.
One structural shift with this release is licensing. Alibaba has confirmed that the Plus tier will be open-source while the Max tier remains proprietary — extending a pattern the company has used since Qwen 3.5. The company also removed the free tier of Qwen Code in the weeks before this release, which suggests the broader product direction is toward monetizing the highest-capability tier while using open models to maintain developer ecosystem presence. For teams building on open-source local AI agent frameworks, the Plus open-weight release will be the practically relevant one, not the Max API.
The Alibaba Cloud Summit on May 21, 2026 is the expected venue for a formal announcement. Whether that announcement includes weight release dates or additional benchmark disclosure will determine how quickly the developer community can verify what the Max preview numbers actually mean at the open-weight tier — a pattern that has repeated with each Qwen generation since the 3.5 series, as AI research tooling built around Qwen's open models has continued to grow alongside the hosted API offerings.
Why Japan Is Losing the AI Race It Helped Create
From language tokenization barriers to corporate risk aversion and venture capital gaps, this explainer breaks down why Japan's AI position lags the US and China.

Google Fires DevRel Engineer Over Workspace CLI
Justin Poehnelt says Google fired him for building a Workspace CLI under the official GitHub org, two days before Google unveiled its own version.
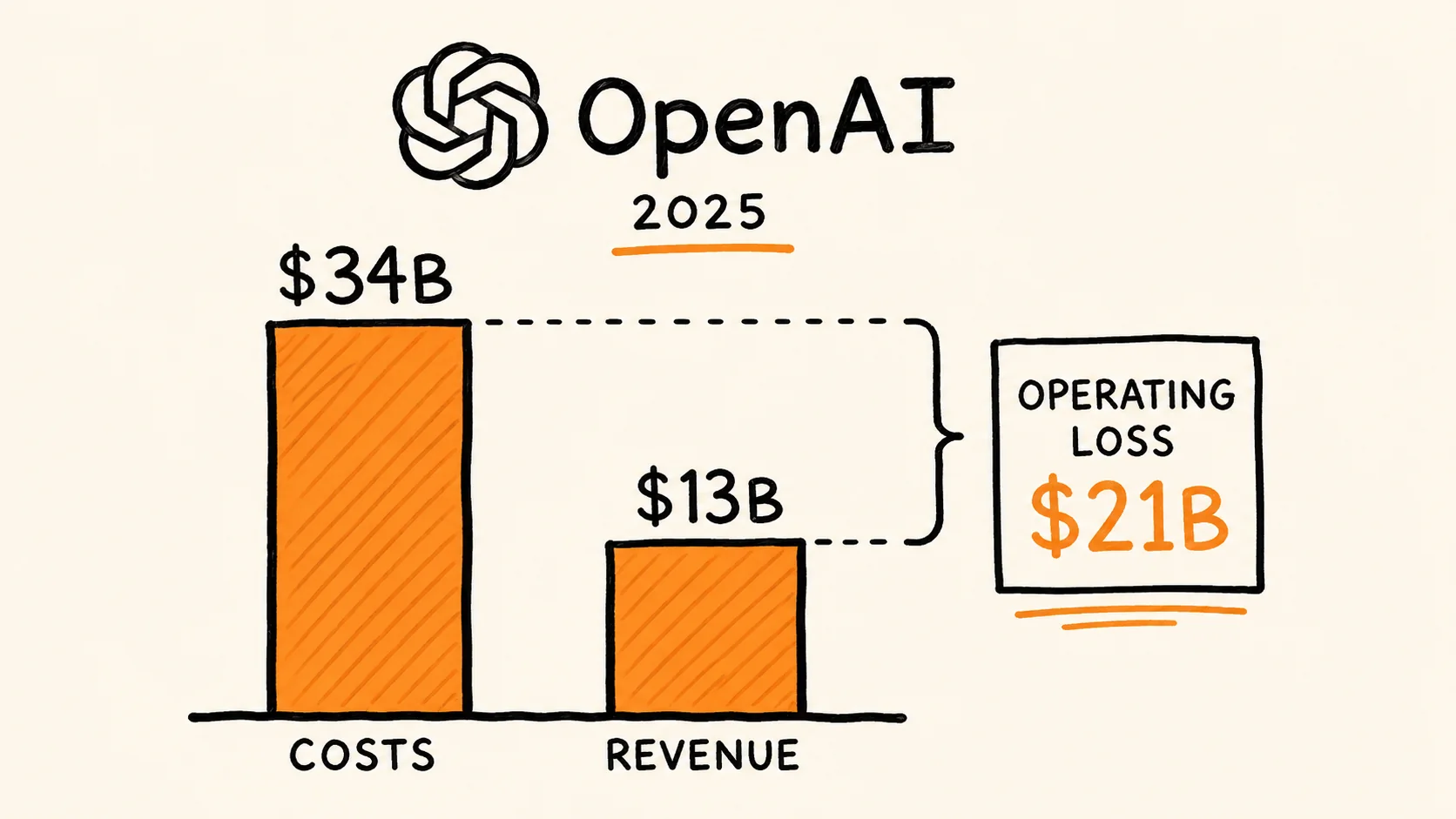
The AI Subsidy Era Is Ending — and Enterprise Buyers Are Getting the Bill
A data-grounded analysis of the AI subsidy model's structural unsustainability, OpenAI's 2025 financial losses, and the 2026 pivot to token-based pricing that is already shocking enterprise customers.

Honor's X80 Pro Max Pairs an 11,000mAh Battery With a Two-Year Free Screen Warranty
Honor launched the X80 Pro Max in China on June 22, 2026, with a record battery, SGS-certified drop resistance, and a free two-year screen warranty.
Comments (0)
Please sign in to join the discussion.
No comments yet.
Be the first to share your perspective on this topic.