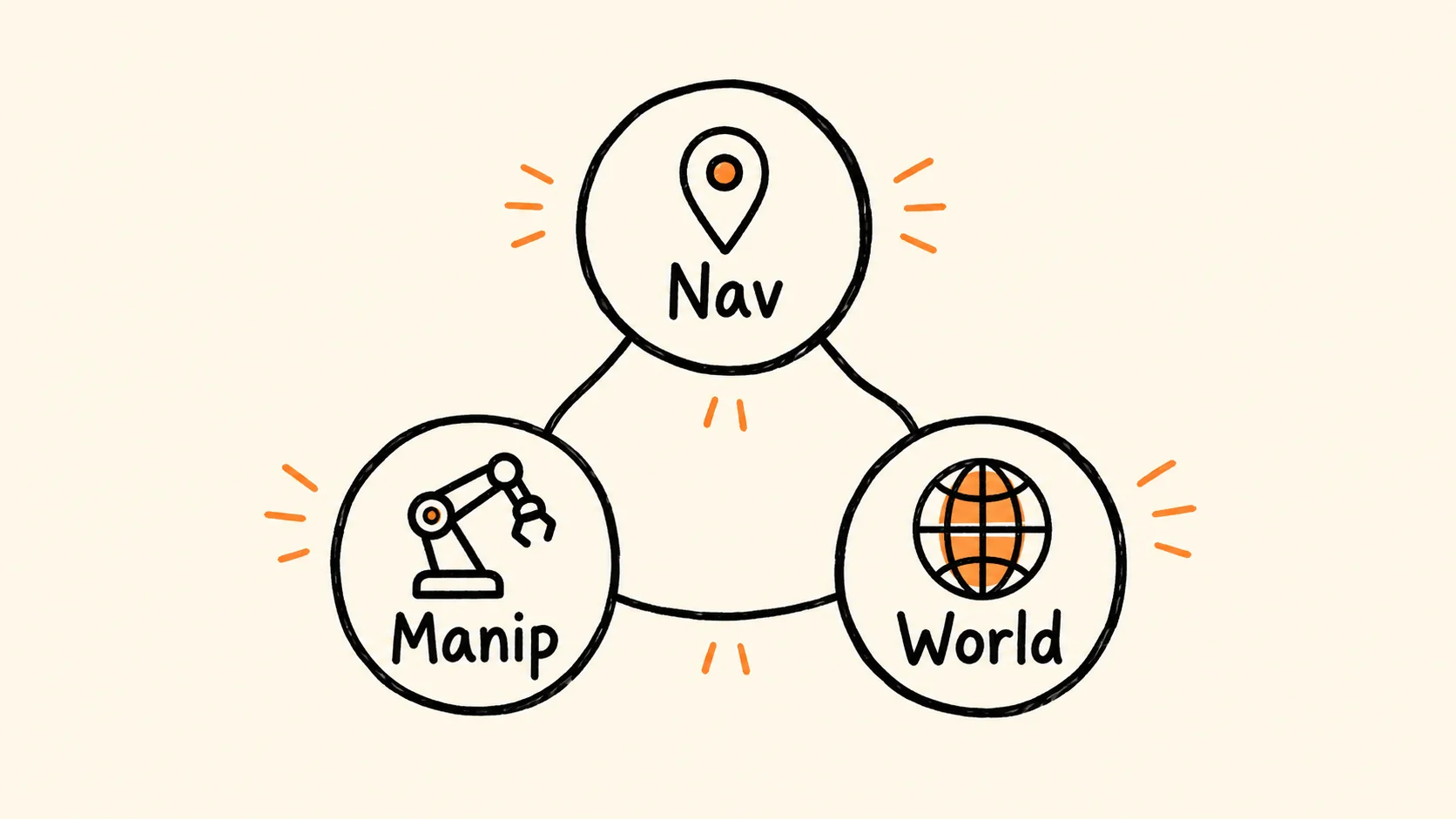
Alibaba's Qwen team has released Qwen-Robot Suite, a set of three foundation models designed to move vision-language intelligence into physical robotic systems. The suite covers navigation, manipulation, and predictive world modeling — each built on a different base, trained at a different scale, and targeting a different constraint in the gap between language understanding and motor execution.

The Core Problem: VLMs Perceive But Cannot Act
Vision-language models have become strong at describing scenes, answering questions about visual content, and reasoning over image sequences. What they cannot do natively is produce the low-level motor commands a physical robot requires. The obstacle is not just architectural — it is data. Embodied training data is heterogeneous across robot embodiments, sparse compared to internet-scale vision-language corpora, and expensive to collect.
Qwen-Robot Suite approaches this by treating each modality gap separately. Qwen-RobotNav handles mobility and spatial reasoning. Qwen-RobotManip handles physical manipulation across diverse robot hardware. Qwen-RobotWorld handles predictive modeling of physical outcomes. The three models are designed to compose, not to replace each other.
The chart below shows the key scale figures published for each model.
Qwen-RobotNav Unifies Five Navigation Tasks Under One Weight Set
Qwen-RobotNav is built on Qwen3-VL and trained on 15.6 million samples, with vision-language co-training running in parallel to preserve the model's grounded perception capacity. The goal is a single set of weights that handles instruction following, object-goal navigation, target tracking, autonomous driving, and embodied question answering — without task-specific branching at inference.
To manage the demands of multi-camera, multi-frame robot observation at inference time, the team introduces a four-axis controllable observation protocol: visual token budget, temporal decay, per-camera weighting, and frame sample mode. These parameters are adjusted at inference without any architectural modification, giving operators a practical handle on compute cost and attention allocation across different hardware configurations.
According to the Qwen blog, the model was deployed zero-shot on a single-camera Unitree Go2 quadruped in environments it had not seen during training. Zero-shot generalization to unseen environments on commodity hardware is a meaningful test because it removes the scaffolding of environment-specific calibration — though the blog does not describe the scope or diversity of the test environments in detail.
The chart below maps the five navigation domains the model is trained to cover.
Qwen-RobotManip Resolves the Cross-Embodiment Data Problem Before Scaling
The manipulation model presents the most technically specific design choice in the suite. Qwen-RobotManip pairs Qwen3.5-4B VL with a flow-matching diffusion transformer action head. The language backbone generates task representations; the DiT head translates those into continuous action trajectories.
The cross-embodiment challenge — training a single policy that transfers across single-arm robots, dual-arm systems, dexterous hands, and mobile bases — historically breaks when you simply aggregate data from different platforms. The reason is representational mismatch: if the feature space used to encode one embodiment's state does not align with another's, adding more data from either platform does not improve joint performance. The Qwen blog states this explicitly: the team found that representation alignment is a strict prerequisite for scaling to work, and that without it, data-scaling curves flatline.
Their resolution is a unified 80-dimensional state-action space and camera-frame end-effector delta poses — a common coordinate system that normalizes action representations across embodiments before any training is done. The training corpus exceeds 38,100 hours of open-source data, including a synthesis pipeline that generated 24,808 hours of robot demonstrations from 1,933 hours of egocentric human video across 15 distinct embodiments. The human-to-robot video synthesis step is the mechanism that allows the training set to scale beyond the volume of available teleoperation data.
On the RoboChallenge Table30 v1 generalist track — a benchmark for policies tested on manipulation tasks across multiple robot types — the model is reported to have ranked first with a 45% success rate. That figure is a vendor-reported leaderboard result and has not been independently replicated in the published literature reviewed here.
Qwen-RobotWorld Models Physical Futures From Natural Language
The third component is architecturally the most unconventional. Qwen-RobotWorld is a language-driven world model: given a current visual observation and a natural-language description of an action, it predicts what the physical environment will look like after that action is executed.
The generator is a 60-layer dual-stream multimodal diffusion transformer. The action encoder is a full VLM — Qwen2.5-VL. Using a VLM as the encoder, rather than a smaller learned embedding, is a deliberate load-bearing choice: the VLM has already internalized a large volume of world knowledge, including physical rules such as object rigidity and gravity. The team's claim is that this knowledge transfers into the generative prediction rather than needing to be relearned from robotics data alone.
Training used the Embodied World Knowledge corpus, comprising 8.6 million video-text pairs covering more than 20 robot embodiments and over 500 action categories within a single interface. The model demonstrates two zero-shot capabilities described in the blog: translating human demonstrations into robot execution sequences without teleoperation, and generating temporally consistent video from multiple viewpoints simultaneously. Neither capability has been evaluated in a published third-party benchmark at the time of this writing.
The Two-Level Agentic System Treats the Three Models as Tool Calls
The three foundation models are not designed to operate independently as task-complete agents. They are positioned as low-level tools callable by a higher-level planner. Alibaba internally refers to this two-level system as Qwen-RobotClaw, with models such as Qwen3.7-Plus or Qwen-Omni serving as the reasoning layer above.
In this architecture the higher-level model handles goal decomposition, long-horizon task sequencing, and replanning when a step fails. The foundation models execute individual physical subtasks — navigate to location X, pick up object Y, predict what happens if action Z is taken — and return results upward. The division allows the reasoning layer to operate without physical grounding while the physical models operate without needing to manage long-horizon state.
Alongside the suite, Alibaba launched Chat2Robot — an experimental browser-based interface, supported by D-Robotics, that lets users send natural-language commands to a live Qwen-RobotManip deployment in real time. The feature is described as experimental and its scope is not fully detailed in the current release. The diagram below shows how the two-level agentic structure connects the planner to the physical model layer.
The suite's architecture reflects a design principle that has become more common in embodied AI research: rather than training a single monolithic generalist agent, decompose the problem into specialized components with well-defined interfaces between them. Whether that decomposition is sufficient to handle the unpredictability of real physical environments — particularly in the long-horizon tasks the planner layer is intended to manage — is a question the current release does not fully answer. The zero-shot navigation and world modeling results described in the blog are demonstrations rather than systematic benchmark evaluations, and the manipulation ranking, while competitive, comes from a single leaderboard submission.

Font-de-Gaume Cave Art Gets Its First Confirmed Radiocarbon Dates
Chemical imaging found charcoal pigment in Font-de-Gaume cave art, letting scientists radiocarbon-date a bison and mask, confirming their Paleolithic age.

Prescribed Burns Cut Giant Sequoia Wildfire Deaths by 77%, Study Finds
A Nature Communications study of 26,403 giant sequoias found prescribed fire cut wildfire mortality odds 77%, already saving nearly 1,900 ancient trees.

Three Venus Rift Valleys May Be Tectonically Active Today
New 3D models of Venus rifts show extension rates of 3–10 cm/yr; wide flank uplifts at Dali, Ganis and Devana Chasmata suggest active rifting, a new study finds.
New Antiviral GHP-88310 Blocks Airborne Measles-Like Transmission in Ferret Study
GHP-88310, an oral antiviral, blocked airborne CDV spread in ferrets and cut sources' contagious period by 5 days, a new Nature Microbiology study finds.
Comments (0)
Please sign in to join the discussion.
No comments yet.
Be the first to share your perspective on this topic.